

刚刚入职公司,结果来了个难题
由于某些特殊原因的情况下, 微服务之间会有耦合交叉;正常情况下只需要跨服务调用即可解决问题,但是当单独服务的数据量达到一定数量级的时候加上跨服务之间的业务场景像极了单个DB下的Join联查的时候,问题也就产生了,怎么实现跨服务间模拟Join联查或者快速实现跨服务的查询。
刚一听到这个东西,我本能的想到各种大数据相关框架的花式姿势组合啊, 数据仓储搞起来啊! 结果领导说,数据部门专门干这个,ETL + OLAP 这种不考虑,不考虑数据写入,只考虑读取。。。。
What mmp ... 然后看了看各种其他的姿势,什么spark SQL 直接操作, 什么TiDB 整理聚合, Canal , Otter , DTS .....
然后领导说,就考虑数据同步吧, 把多个数据库同步到同一个数据库的不同schema, 这样不就能直接用来join 啦?
然后就走起呗, 简单起见,又不想写代码, 选择了Otter
==================================================
然后记录一下Otter 的搭建过程
otter 环境搭建操作手册
总的来说,搭建DEMO式可用的otter环境很简单,关键在于HA和异常时如何让他快速恢复、压测时的延时如何尽可能短,TPS尽可能高。(这里没有考虑 manager的HA)

1. 安装jdk 8
a. 首先到官网下载jdk-8u66-linux-x64.tar.gz, http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
b. 解压到 /usr/local/java
sudo mkdir /usr/local/java
cp jdk-8u66-linux-x64.tar.gz /usr/local/java
cd /usr/local/java
sudo tar zxvf jdk-8u66-linux-x64.tar.gz
sudo rm jdk-8u66-linux-x64.tar.gz
c.设置jdk环境变量
vi /etc/profile
JAVA_HOME=/usr/local/java/jdk1.8.0_66
JRE_HOME=/usr/local/java/jdk1.8.0_66/jre
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
PATH=$JAVA_HOME/bin:$PATH
export PATH JAVA_HOME CLASSPATH
source /etc/profile
如果系统已经安装了其他版本的Java修改默认JDK
update-alternatives --install /usr/bin/java java /usr/java/jdk1.8.0_66/bin/java 300
update-alternatives --install /usr/bin/javac javac /usr/java/jdk1.8.0_66/bin/javac 300
update-alternatives --config java
update-alternatives --config javac
2. 安装mysql 5.7
CentOS6.5 YUM 安装MySQL5.7:
https://www.cnblogs.com/lzj0218/p/5724446.html
CentOS6.5 RPM 安装MySQL5.7
https://blog.csdn.net/dongweizu33/article/details/78053540
mysql 开启binlog的配置
搭建一个数据库同步任务,源数据库必须开启binlog,并且binlog_format为ROW,即在mysql的配置文件加上以下两行
log-bin=mysql-bin
binlog-format=ROW
如果源库已开启binlog,通过mysql客户端命令show master status查看

3.安装 ZooKeeper 4.x
如果已有zk集群可以跳过;
这里直接用测试环境的三台机器弄了个集群了
4.Node 节点安装aria2
Yum 安装: https://www.htcp.net/3652.html
源码包安装:https://www.moerats.com/archives/800/
设置开机启动
vi /lib/systemd/system/aria2.service
[Unit]
Description= aria2
After=network.target
[Service]
ExecStart=/usr/bin/aria2c --conf-path=/opt/data/aria2/conf/aria2.conf &
ExecStop=kill -9 $MAINPID
RestartSec=always
[Install]
WantedBy=multi-user.target
systemctl daemon-reload
systemctl enable aria2.service
systemctl start aria2.service
systemctl status aria2.service
5.安装并配置manager
- 下载 manager 发布包: https://github.com/alibaba/otter/releases
- 解压到 /opt/data/otter-manager
- 下载MySQL初始话sql 并执行
wget https://raw.github.com/alibaba/otter/master/manager/deployer/src/main/resources/sql/otter-manager-schema.sql
mysql -u root -p
#输入mysql密码
source /opt/pkgs/otter-manager-schema.sql
导入初始化sql 有问题, 时间默认值为0是不可以的,需要修改sql-mode
show variables like 'sql_mode';
set session sql_mode='ONLY_FULL_GROUP_BY,NO_AUTO_VALUE_ON_ZERO,STRICT_TRANS_TABLES,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION';
- 修改manager 配置文件 vim conf/otter.properties
[root@v-03-01-00223 conf]# cat otter.properties 红色是注意需要修改的地方
## otter manager domain name
otter.domainName = 172.28.1.97 ## 建议改成所在服务器的ip,而不是默认的127.0.0.1,否则到时候启动的时候所有的连接指向的目标都是localhost,因为通常otter跑在linux环境,很多linux环境是没有图形化界面的,感觉这是个bug
## otter manager http port
otter.port = 8088 ## 如果非专用或者已经有了一些web应用在同一台服务器,建议改成其他的避免端口冲突,这里的端口号要和jetty.xml中的保持一致,这里也是,直接用个非8080端口就更友好了,比如weblogic 控制台7001,es控制台9200,rabbitmq控制台15672
## jetty web config xml
otter.jetty = jetty.xml
## otter manager database config
otter.database.driver.class.name = com.mysql.jdbc.Driver
otter.database.driver.url = jdbc:mysql://127.0.0.1:3308/otter ## otter配置信息维护的数据库地址,库名一般为otter/otter_manager/manager
otter.database.driver.username = root
otter.database.driver.password = 123456
## otter communication port
otter.communication.manager.port = 1099 ## node和manager通信的接口,一般不用修改
## otter communication pool size
otter.communication.pool.size = 10
## default zookeeper address
otter.zookeeper.cluster.default = 127.0.0.1:2181 ## zk地址
## default zookeeper sesstion timeout = 60s
otter.zookeeper.sessionTimeout = 60000
## otter arbitrate connect manager config
otter.manager.address = ${otter.domainName}:${otter.communication.manager.port}
## should run in product mode , true/false
otter.manager.productionMode = true
## self-monitor enable or disable
otter.manager.monitor.self.enable = true
## self-montir interval , default 120s
otter.manager.monitor.self.interval = 120
## auto-recovery paused enable or disable
otter.manager.monitor.recovery.paused = true
# manager email user config
otter.manager.monitor.email.host = smtp.gmail.com
otter.manager.monitor.email.username =
otter.manager.monitor.email.password =
otter.manager.monitor.email.stmp.port = 465
- 启动manager ./bin/startup.sh (manager 编译时间大约需要1分钟)
- 检查日志: cat logs/manager.log
6. 安装并配置Node
- 下载 node 发布包: https://github.com/alibaba/otter/releases
- 解压到 /usr/local/app/node
- 关联manager,zookeeper和node
- 先进入manager的管理界面,点击右边的登陆:

- 使用默认用户名密码admin:admin登陆进去:

- 找到机器管理的zookeeper配置点击进去:

- 选择添加一个zookeeper:

- 填好自己本地的zookeeper地址和端口保存:

- 在选择机器管理的node管理点击进去:

- 选择添加一个node:

- 配置好node的一些参数
- 机器名称:可以随意定义,方便自己记忆即可
- 机器ip:对应node节点将要部署的机器ip,如果有多ip时,可选择其中一个ip进行暴露. (此ip是整个集群通讯的入口,实际情况千万别使用127.0.0.1,否则多个机器的node节点会无法识别)
- 机器端口:对应node节点将要部署时启动的数据通讯端口,建议值:2088
- 下载端口:对应node节点将要部署时启动的数据下载端口,建议值:9090
- 外部ip :对应node节点将要部署的机器ip,存在的一个外部ip,允许通讯的时候走公网处理。
- zookeeper集群:为提升通讯效率,不同机房的机器可选择就近的zookeeper集群.
node这种设计,是为解决单机部署多实例而设计的,允许单机多node指定不同的端口:

修改node配置的nid
cd /usr/local/app/node/
# nid配置node的ID多个node协同工作时不能重复
echo 1 > conf/nid
# 修改配置文件
vim conf/otter.properties
# 主要是确认连接manager地址是否正确(这里使用服务器内网地址进行配置)
otter.manager.address = 10.144.159.182:1099
启动node ./bin/ startup.sh
查看日志:cat logs/node.log
7.同步任务配置
分为下列几个步骤(不熟悉术语概念的建议回到页首重新review下):
1、添加canal


点位可以通过在主库执行show master status和select unix_timestamp()得到。

2、添加数据源
设置主库和从库的数据源


3、添加同步表


4、添加channel
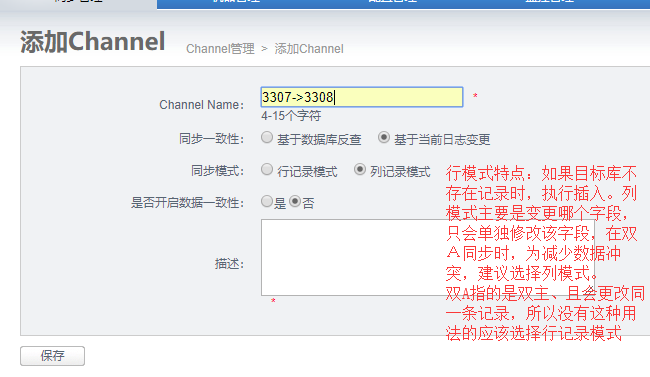
5、添加pipeline
pipeline里面主要选择节点和canal。
6、添加映射关系


7、启动同步

注意:默认会同步ddl,对于分库分表同步到从库的时候,建议不要同步ddl以及跳过ddl。
插入数据试试看吧。。。。
otter同步异常问题排查与监控
笔者一开始启动后,确实报错了,如下:

基于Docker 搭建otter 的环境
参照连接: https://blog.csdn.net/littlebrain4solving/article/details/79238399?utm_source=blogxgwz7
附录
- Otter 架构简介
otter的总体架构

otter强依赖于canal,并对canal的配置有一定的约束。也正是因为强约束,在node中集成了canal,canal作为node的线程运行,使用otter搭建mysql同步环境不需要先手工搭建canal。在开始进入搭建环节之前,建议先看下术语,除非很清楚了,不然相信我,你还是要回过头来看的。
- Pipeline:从源端到目标端的整个过程描述,主要由一些同步映射过程组成
- Channel:同步通道,单向同步中一个Pipeline组成,在双向同步中有两个Pipeline组成
- DataMediaPair:根据业务表定义映射关系,比如源表和目标表,字段映射,字段组等
- DataMedia : 抽象的数据介质概念,可以理解为数据表/mq队列定义
- DataMediaSource : 抽象的数据介质源信息,补充描述DateMedia
- ColumnPair : 定义字段映射关系
- ColumnGroup : 定义字段映射组
- Node : 处理同步过程的工作节点,对应一个jvm
他们之间的关系为:

HA 方案:待考虑
- 初始化slave
启动主从同步后,master不一定会有所有的binlog,那么原有的数据是通过什么方式传到slave上的?
比如master上有5000条数据,之后开启binlog和主从同步,那么就只有5001条之后的数据会从binlog同步到slave,那之前的5000条数据是怎么传到slave上的
主从同步开启时,主库的旧数据是不会自动同步到从库的,需要执行mysqldump先把数据dump出来,导入到slave中去,然后再start slave。
注意如果需要不停机的开启主从同步,可以尝试在mysqldump添加--master-data的参数,这样导入从库之后会自动设置binlog的位点。
- 源数据库需要做的设置
### master 配置
# 开启binlog
log-bin=mysql-bin
# 设置server-id 唯一标识
server-id=1
# 控制以什么格式记录二进制日志的内容 statement|row|mixed,默认是mixed, 这里需要设置成 row
binlog_format=row
# 设置自动删除 binlog日志的时间 为15天 默认为0
#expire_logs_days=15
# 此参数表示在事务提交时,处理重做日志的方式;此变量有三个可选值0,1,2:
#0:当事务提交时,并不将事务的重做日志写入日志文件,而是等待每秒刷新一次
#1:当事务提交时,将重做日志缓存的内容同步写到磁盘日志文件,为了保证数据一致性,在replication环境中使用此值。
#2:当事务提交时,将重做日志缓存的内容异步写到磁盘日志文件(写到文件系统缓存中)
innodb_flush_log_at_trx_commit=1
#gtid 看mysql 版本来设置是否开启
结束语
有些步骤可能不太完美,只是记录一下搭建过程