

背景
本篇博客是接着上篇博客写的,若未查看上篇博客请先查看,配置伪分布式是配置分布式的基础。
网络配置
1、关闭master虚拟机,手动复制两台虚拟机(需保证伪分布式也配置成功,所有配置文件都配置好了),点击鼠标右键复制粘贴,
在这里另外两个虚拟机命名为slave1和slave2。下图是复制完成的状态。

2、更改主机名称:sudo vim /etc/hostname
slave1这台虚拟机中写slave1;slave2这台虚拟机中写slave2;

3、配置域名和ip的对应关系:sudo vim /etc/hosts
3台虚拟机都要如此编写。

4、配置网卡sudo vim /etc/network/interfaces
在此只需把address更改为192.168.56.101即可。slave2中改为192.168.56.102。

5、使用Bitvise SSH 进行登录,注意ip,并另存在桌面,方便登录。


6、测试是否相互 ping 得通:ping slave1 -c 3(只ping 3次,否则要按 Ctrl+c 中断)。

7、修改完成后需要重启一下,重启后在终端中才会看到机器名的变化。
SSH无密码登陆节点
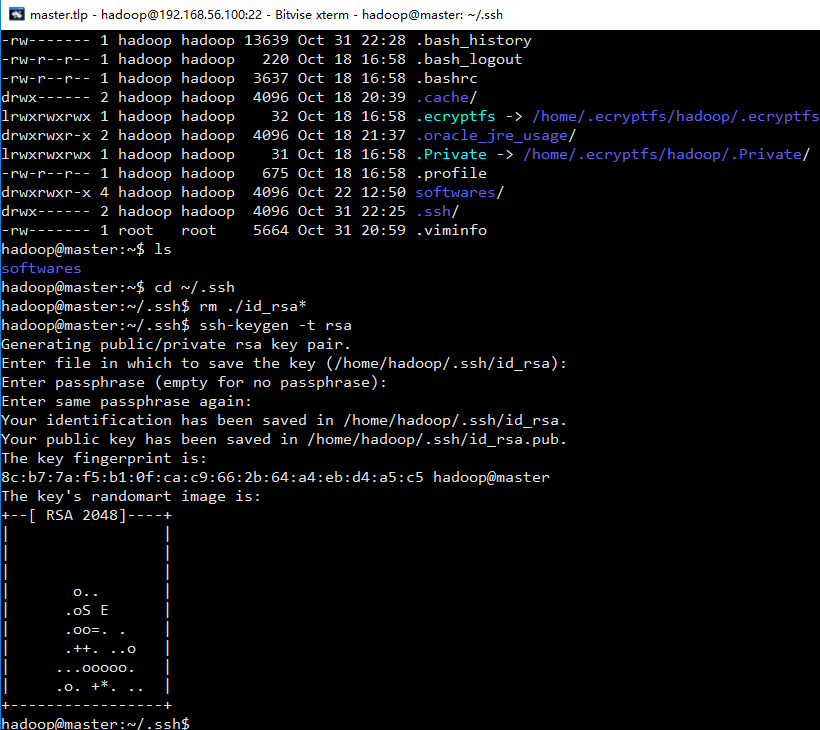
1、使用如下命令登陆本机:ssh master
2、进入该目录 :cd ~/.ssh
3、删除之前生成的公匙(如果有):rm ./id_rsa*
4、生成 master 节点的公匙:ssh-keygen -t rsa(一直按回车就可以)
5、将密钥加入到授权中:cp id_rsa.pub authorized_keys (让 master 节点能无密码 登录SSH 本机)
6、在 master 节点将上公匙传输到 slave1 节点:
scp ~/.ssh/id_rsa.pub hadoop@slave1:/home/hadoop/
7、接着在 slave1 节点上,将 ssh 公匙加入授权:
(1)mkdir ~/.ssh ( 如果不存在该文件夹需先创建,若已存在则忽略)
(2)将密钥加入到授权中:cp id_rsa.pub authorized_keys
(3)rm ~/id_rsa.pub (用完就可以删掉了)
8、对slave2也进行步骤6、7的操作。
9、进行检验:ssh slave1
10、格式化主节点hahadoop@master:~/softwares/hadoop-2.6.0$ bin/hadoop namenode –format
11、启动分布式文件系统
hadoop@master:~/softwares/hadoop-2.6.0$ sbin/start-dfs.sh
12、启动完成以后使用jps命令查看进程。
master节点中:

slave1节点中:

slave2节点中:

13、再启动start-yarn.sh
mr-jobhistory-daemon.sh start historyserver
可以在master 节点上可以看到 NameNode、ResourceManager、SecondrryNameNode、JobHistoryServer 进程。
在 Slave 节点可以看到 DataNode 和 NodeManager 进程。
14、在master 节点上通过命令 hdfs dfsadmin -report 查看
DataNode 是否正常启动,如果 Live datanodes 不为 0 ,则说明集群启动成功。

15、一些小问题:
(1)查看ssh-keygen的用法:ssh-keygen -

(2)查看ssh中有什么

执行测试程序wordcount(分布式)
在master节点中建立输入输出文件(同伪分布式相同)。

在slave1,slave2中查看结果。

