












首先是图分割方法,分成多块。Metis 运行比较快。

形成抽象图,每个节点成为 抽象节点,边是有权值的
抽象网络可以 描绘 global view

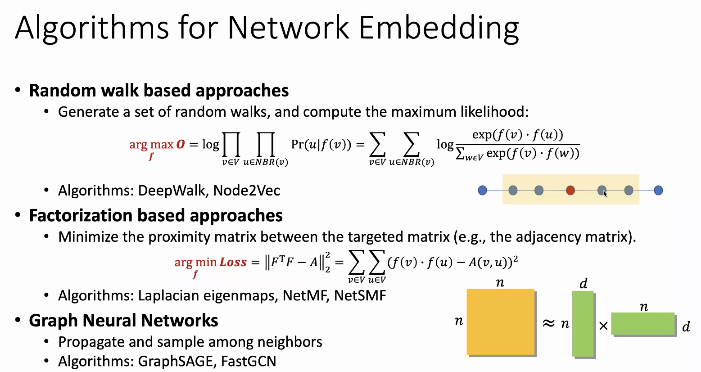
采用随机游走方法,需要生成一堆随机游走路径,带权重的话归一化处理,作为选取概率,Alias 方法。O(1)复杂度
Alias 方法:a family of efficient algorithms for sampling from a discrete probability distribution, due to A. J. Walker.[1][2] i.e., it returns integer values 1 ≤ i ≤ n according to some arbitrary probability distribution pi. The algorithms typically use O(n log n) or O(n) preprocessing time, after which random values can be drawn from the distribution in O(1) time.[3]

这个和HARP方法不一样,通过传播的方式,赋给节点向量,多次迭代,把邻居的初始向量加权平均,再和自身平均,多次迭代后得到初始向量,和邻居尽可能相似,和图表征网络很像,空间向量相似。

最大联通子图,做随机预测,node2vec is an algorithm to generate vector representations of nodes on a graph. The node2vec framework learns low-dimensional representations for nodes in a graph through the use of random walks through a graph starting at a target node. It is useful for a variety of machine learning applications. Besides reducing the engineering effort, representations learned by the algorithm lead to greater predictive power. node2vec follows the intuition that random walks through a graph can be treated like sentences in a corpus. Each node in a graph is treated like an individual word, and a random walk is treated as a sentence. By feeding these "sentences" into a skip-gram, or by using the continuous bag of words model paths found by random walks can be treated as sentences, and traditional data-mining techniques for documents can be used. The algorithm generalizes prior work which is based on rigid notions of network neighborhoods, and argues that the added flexibility in exploring neighborhoods is the key to learning richer representations of nodes in graphs.The algorithm is an extension of Gensim's word2vec algorithm, and is considered one of the best classifiers for nodes in a graph.


游戏里给玩家推荐好友,帮派、战队推荐,推荐任务。道具推荐,根据社交网络有相关性。

初始化超参数的选择很重要,通过机器学习确定超参数选择,相似的图有相似的超参数选择。注:超参数的概念(hyperparameter),指的是通过模型训练学习出来的。通常我们所说的调参,就是调节超参数,例如通过反复是错来找到超参数合适的值。在少数情况下,超参数也可以通过模型训练学出。
提问环节:
- 知识蒸馏,模型压缩(模型较为复杂时,特别大,线上先做蒸馏,更快,要不然延迟比较大)
- 模型安全(防止attack)
- 图划分 的优势是什么? Bridge 合成一个点了,两个区域合成一个,会有信息丢失。图划分对 bridge 节点有什么特殊处理。
- 推荐的时候,是否考虑道具的效率(feature, utility), insentive, 持续玩,attract 做 game theory 可以用来做。
论文下载:
- Initialization for Network Embedding: A Graph Partition Approach.pdf
- Harp: Hierarchical representation learning for networks.pdf
- node2vec: Scalable Feature Learning for Networks.pdf
- DeepWalk: Online Learning of Social Representations.pdf
- LINE: Large-scale Information Network Embedding.pdf